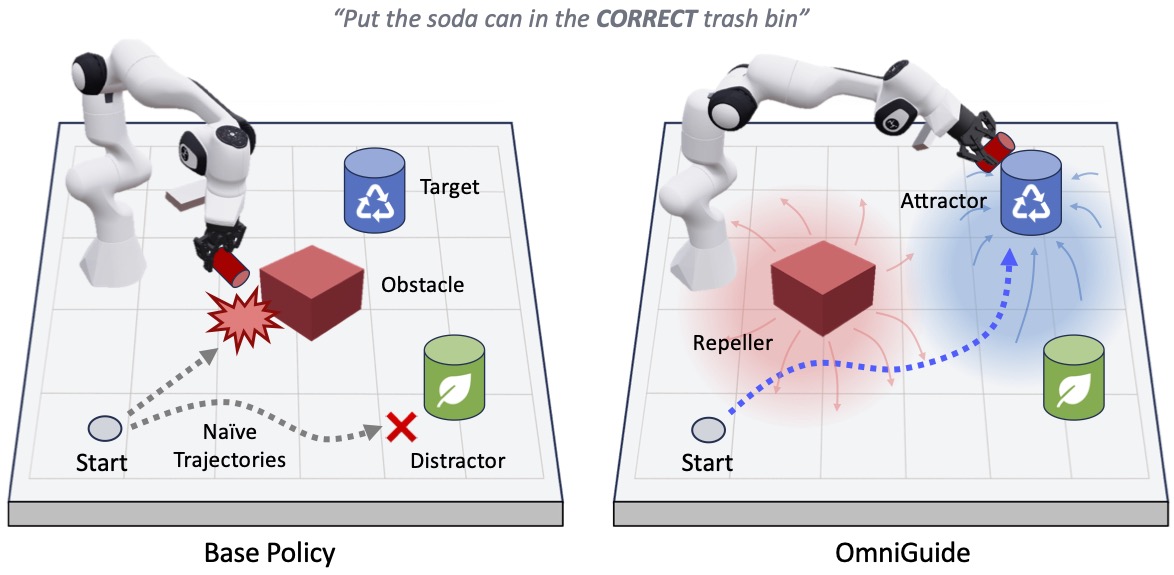
OmniGuide works with any generative policy (Diffusion or Flow Matching) by steering the robot's towards task-relevant regions (attractors) and away from collision obstacles (repellers). During the denoising process, we estimate the "clean" action, project it into 3D Cartesian space ($X$) using a differentiable kinematics model, and calculate a task-specific energy $\mathcal{L}_y(X)$. We then use the gradient of this energy to steer the robot's plan:
$$A^{\tau+\delta} = A^\tau + \delta \left( v_\theta(A^\tau, o) - \lambda \text{clip}(\nabla_{A^\tau} \mathcal{L}_y(X), \alpha) \right)$$
This allows us to blend the VLA’s natural movement with external "expert" knowledge from other foundation models. We experimented with three modalities of guidance: collision avoidance, semantic grounding, and human imitation.